
How are inverted indexes used ?
Have you ever wondered how search engines and libraries like Lucene, Solr and Elasticsearch work?
They use inverted indexes which are faster and more efficient than forward indexes since the document database doesn’t need to perform a full table scan. They are a fundamental component of keyword search.
Almost every software that does Information Retrieval uses some kind of inverted index since you don’t go through a list of documents hoping to find the match, you go through a list of documents that you already know contains the match.
How do inverted indexes work ?
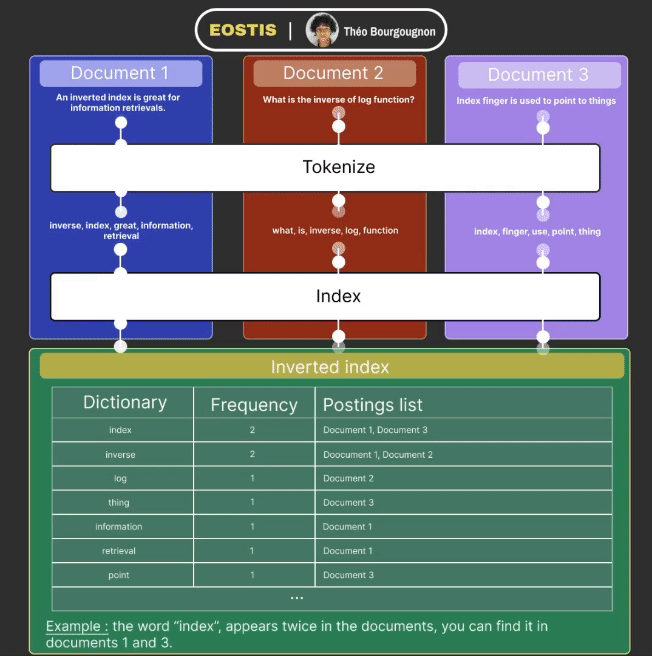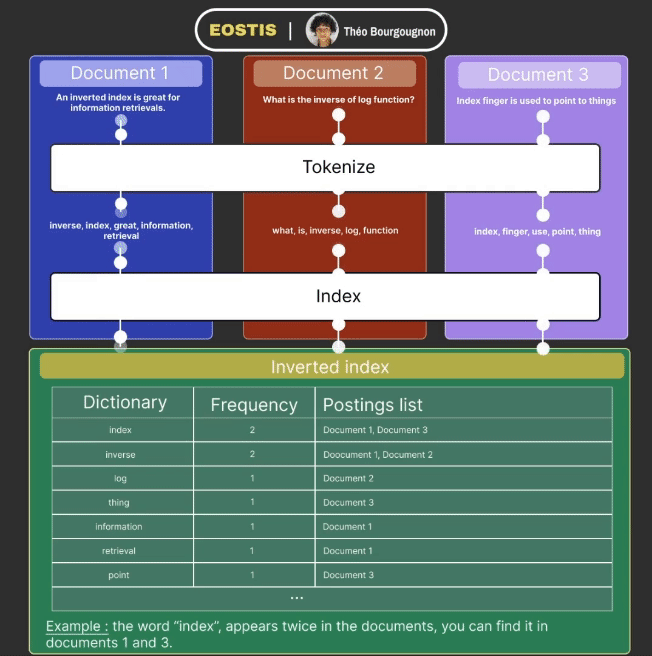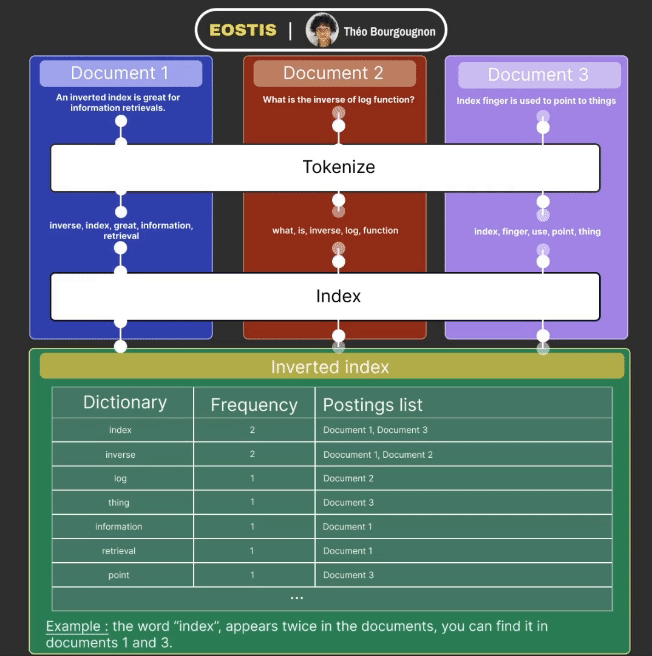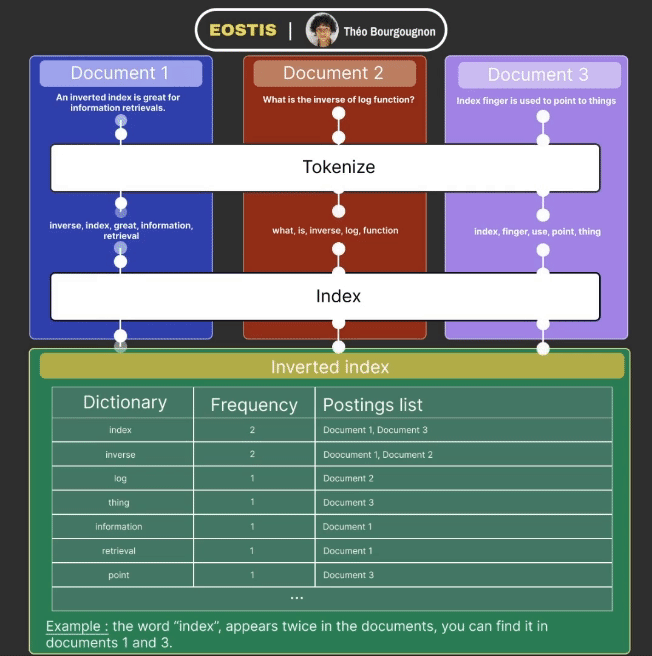
Indexation works in a few steps :
- The data received is tokenized : it simplifies each word of the document (ex: removes the plural, verbs to infinitives, etc).
- The data is added to the inverted index and is composed of three columns :
- The dictionary column contains one of every token from the documents, one per row.
- Frequency column corresponds to the number of times a specific token appears in total in the documents.
- Postings list column maps a specific token to all the documents in which it appears.
How to add keyword search to WordPress websites ?
You can learn how to add keyword search to your WordPress website using our detailed guide.
