This short introduction to Elasticsearch and Solr server should help you start quicker with Elasticsearch / Solr installation and configuration.
Elasticsearch and Apache Solr are open source search engines. In fact, they are the most widely used search servers.
Algolia is a SaaS search service. You pay for the resources you consume (number of documents indexed, number of queries performed).
Search engine
A full-text search engine is built from the ground to tackle problems that a SQL search find difficult or impossible.
The list of those features is huge: multi-language, dedicated plugins to extend the engine, synonyms, stop words, facets, boosts, …
The core search engine of Elasticsearch and Apache Solr is Apache Lucene.
Api
Elasticsearch and Apache Solr are web applications. A client will use their http API to query or store data.
Open source
The source code of Elasticsearch and Apache Solr are respectively maintained by Elasticsearch BV and the Apache foundation. You can read the code, and even contribute to improve/patch/add features.
Behind the scene
Elasticsearch and Apache Solr are written in java, and live in a http java container. In previous versions, Solr was deployed in a Tomcat container.
Configuration of Elasticsearch indexes
Elasticsearch index configuration is done with HTTP / JSON commands. No files required. You define types, mappings, analysis with simple commands.
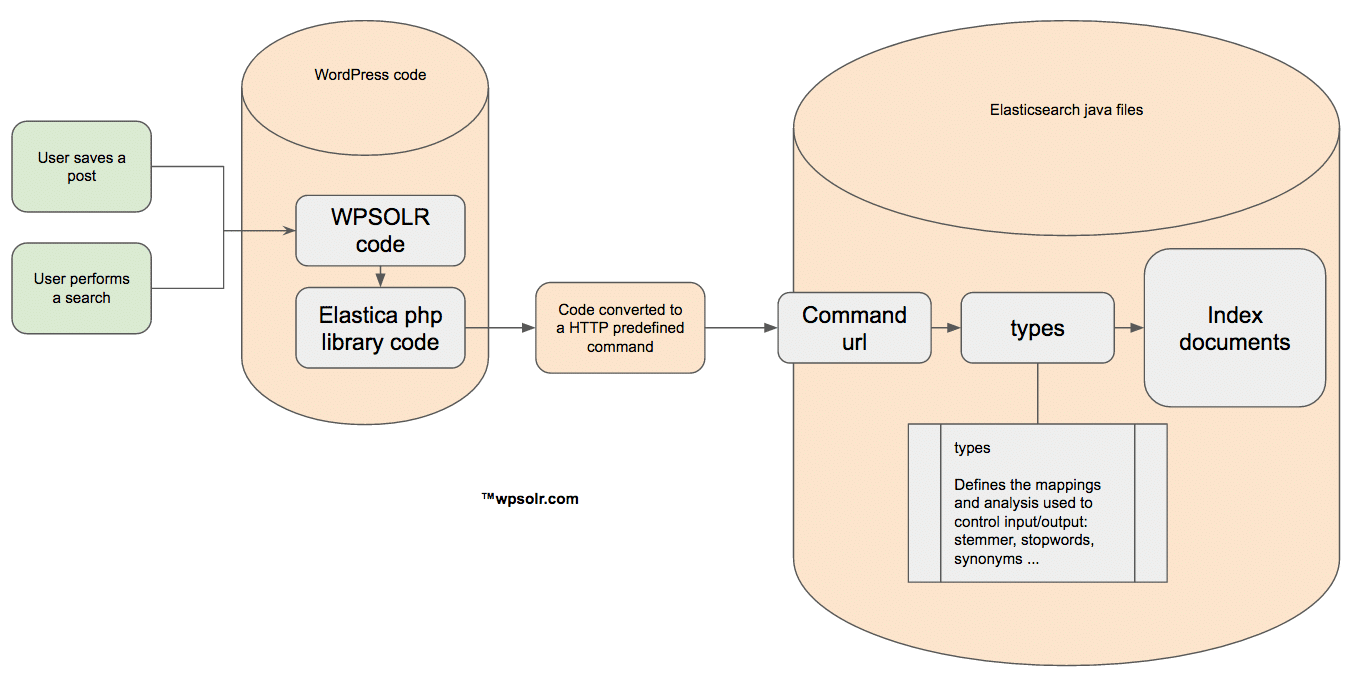
Configuration of Solr indexes
Solr index configuration is done through 2 files: schema.xml and solrconfig.xml.
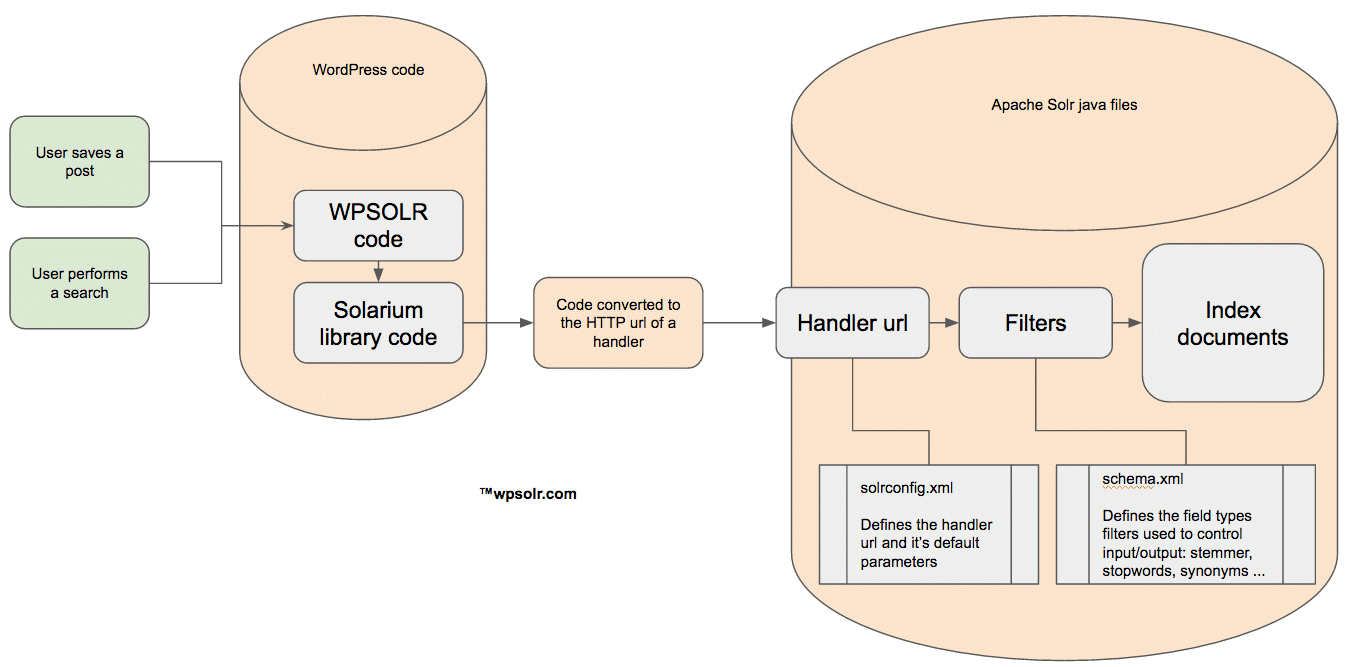
solrconfig.xml is configuring the “handlers”. Handlers are urls (remember the HTTP api above), executing plugins (java code) with their default configuration.
schema.xml is configuring your document structure (a document is made of fields with field types), and how field types are processed during indexing and querying.